Showcase
Focus on 4CAT
Open this showcase in other interactive and executable environments:
![]()
![]()
![]()
Background
Ths showcase has two different goals:
- Exemplary presentation of the collection of
 Reddit data using the RedditExtractoR package
Reddit data using the RedditExtractoR package - Importing and analyzing the data collected with the 🐈🐈 4CAT 🐈🐈 (Peeters & Hagen, 2022) tool.
Data collection with RedditExtractor
Reddit Extractor is an R package for extracting data out of Reddit. It allows you to:
- find subreddits based on a search query
- find a user and their Reddit history
- find URLs to threads of interest and retrieve comments out of these threads
Unfortunately, the functions of the RedditExtractoR package can NOT be executed during the Markdown creation process and must be reproduced “live”.
Therefore, there will be no output for the next two paragraphs.
Example: Find subreddits
Similar to the example from the seminar, the function find_subreddits identifies all subreddits that contain the keyword news either in their name or in their attributes.
library(tidyverse)
library(RedditExtractoR)
# Get list of subreddits
news <- find_subreddits("news")
# Quick preview of the dataset
news %>% glimpse()
# Arrange subreddits by subscribers
news %>%
arrange(-subscribers) %>%
tibble() %>% head()Example: Find thread URLs
# Get list of top thread urls
news_top_urls <- find_thread_urls(
subreddit = "news",
sort_by = "top",
period = "month"
)
# Quick preview of dataset
news_top_urls %>% glimpse()
news_top_urls %>% tibble()Analysis of collected 🐈🐈 4CAT 🐈🐈 data
A detailed description about the collection of the data (in the form of a concrete application example) can be found in the slides of the associated session.
Load data into local environment
# load packages
library(readr)
library(here)
# get data from github
musk <- read_csv(
here("content/06-api_access-reddit/data.local/4cat-reddit_news-musk_complete.csv"))
musk_entities <- read_csv(
here("content/06-api_access-reddit/data.local/4cat-reddit_news-musk-named_entities.csv"))
# Anonymization of potentially sensitive information
musk_hash <- musk %>%
mutate(
across(c(
thread_id:id,
body, author:post_flair,
parent),
~ v_digest(.)))
# quick preview
musk_hash %>% glimpse()Rows: 4,838
Columns: 16
$ thread_id <chr> "fa3188370daf15e630f9121ab7e1ff76", "e00fff6599660fbfd7…
$ id <chr> "0427331b4ed6b36be917779e839c732f", "9465790a781133af6b…
$ timestamp <dttm> 2022-11-14 00:13:59, 2022-11-14 01:11:53, 2022-11-14 0…
$ body <chr> "a82402045c5afcce8e1e20c9d3d7978a", "f07ff47103d975865a…
$ subject <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ author <chr> "736bbd33d9055a81d41f1f0aa12859c2", "89a6bdaaa7351e189a…
$ author_flair <chr> "9c63023a4dad721af7dc04902c9ddecb", "9c63023a4dad721af7…
$ post_flair <chr> "9b09f05e8ca418b2b85266625985528b", "9b09f05e8ca418b2b8…
$ domain <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ url <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ image_file <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ image_md5 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ subreddit <chr> "worldnews", "news", "news", "news", "news", "news", "n…
$ parent <chr> "e1ef5b33cbd8891c1a005cf5521d1408", "e342d97798ff809247…
$ score <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ unix_timestamp <dbl> 1668384839, 1668388313, 1668391383, 1668391676, 1668391…musk_entities %>% glimpse()Rows: 3,633
Columns: 3
$ word <chr> "musk", "twitter", "twitter", "elon musk", "tesla", "trump", "t…
$ entity <chr> "PERSON", "PERSON", "PRODUCT", "PRODUCT", "ORG", "ORG", "GPE", …
$ count <dbl> 1147, 861, 479, 404, 345, 273, 222, 218, 205, 187, 154, 132, 13…Messages including ‘musk’ over time
The following graphics (and especially their labels) may appear very small. To view the graphics in their original size, right-click on the images and select “Open image/graphic in new tab”.
Total
library(lubridate)
library(sjPlot)
# Display
musk %>%
mutate(date = as.factor(date(timestamp))) %>%
plot_frq(
date,
title = "Post including 'musk' on Reddit") +
labs(subtitle = "Subreddits 'news' & 'worldnews' between 14-11 and 26-11-2022")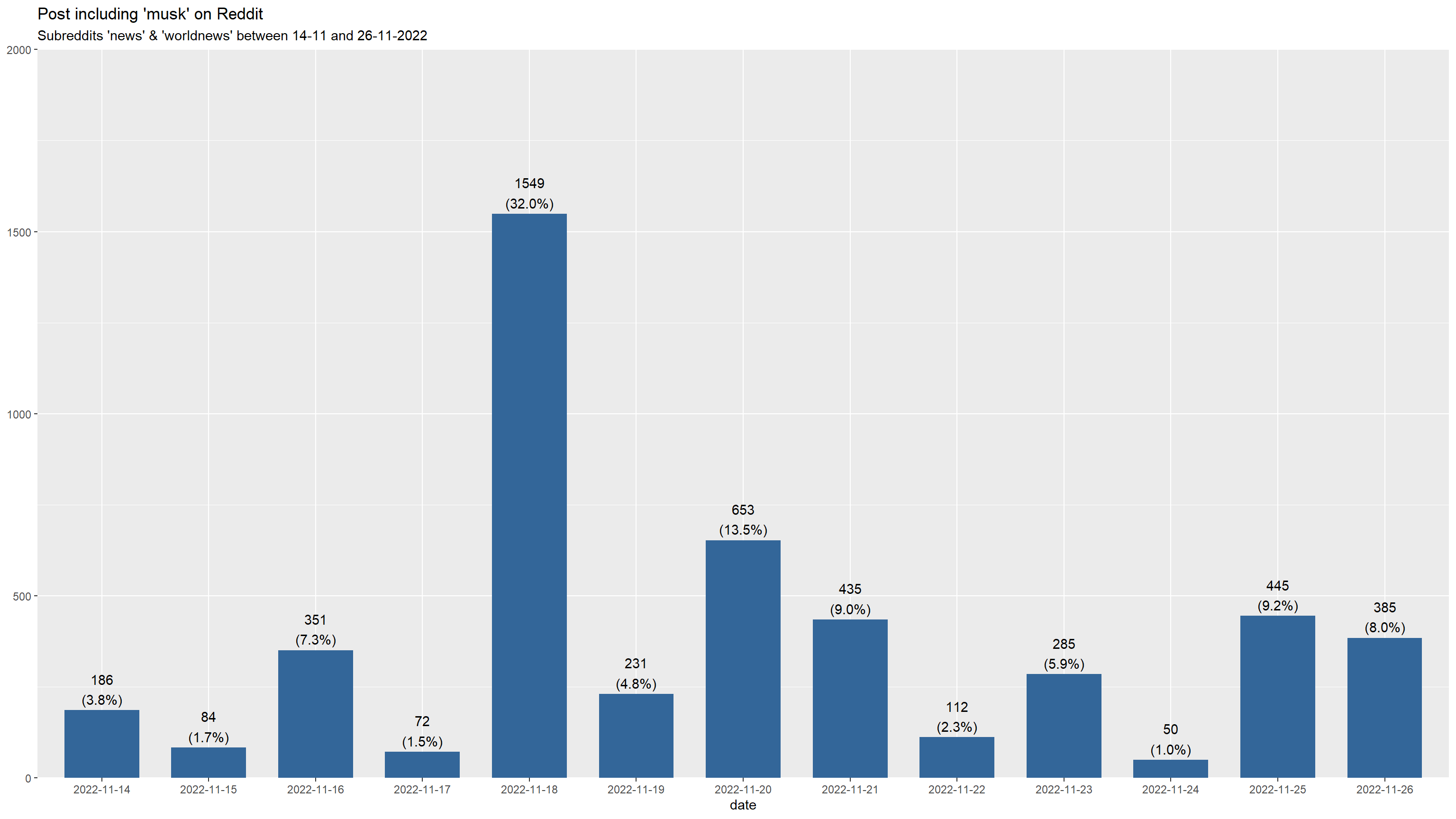
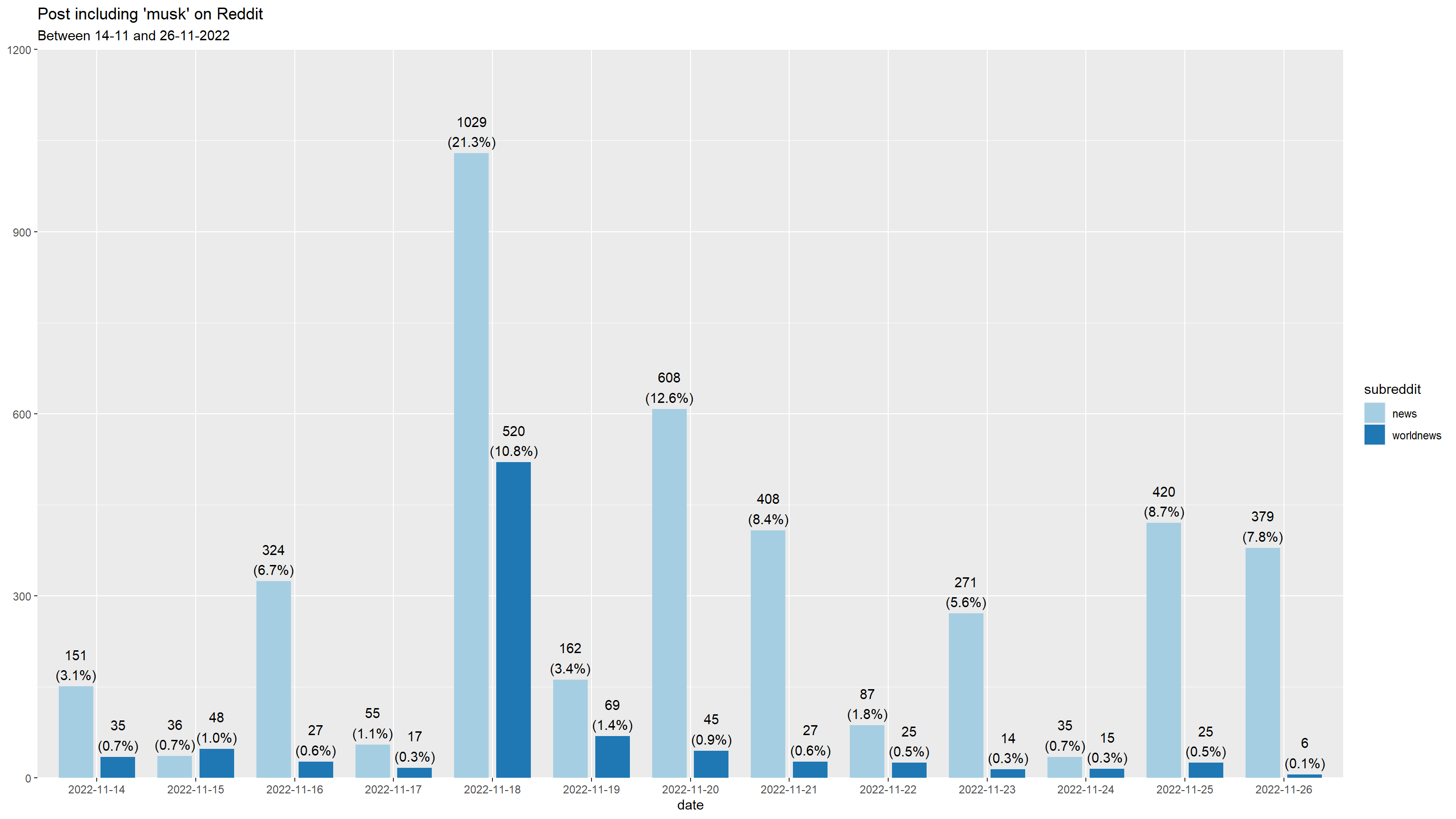
By subreddit
library(magrittr)
musk %>%
mutate(
date = as.factor(date(timestamp)),
across(subreddit, as.factor)
) %$%
plot_grpfrq(
date,
subreddit,
title = "Post including 'musk' on Reddit") +
labs(subtitle = "Between 14-11 and 26-11-2022")