Web-Scraping – TikTok
Digital behavioral data - Session 07
07.12.2022
Seminarplan
| Sitzung | Datum | Thema | Referent*Innen |
|---|---|---|---|
| 1 | 26.10.2022 | Kick-Off Session | Christoph Adrian |
| 2 | 02.11.2022 | DBD: Einführung und Überblick | Christoph Adrian |
| 3 | 09.11.2022 | DBD: Datenerhebung | Christoph Adrian |
| 4 | 16.11.2022 | API-Access (I): Twitter | Falk |
| 5 | 23.11.2022 | API-Access (II): YouTube | Denisov |
| 6 | 30.11.2022 | API-Access (II): Reddit | Landauer |
| 7 | 07.12.2022 | Webscraping: TikTok | Brand & Kocher |
| 8 | 14.12.2022 | Exkurs: DBD Analyse mit R | Christoph Adrian |
| WEIHNACHTSPAUSE | |||
| 9 | 11.01.2023 | ESM: m-path | Dörr |
| 10 | 18.01.2023 | Data Donations | Hofmann & Wierzbicki |
| 11 | 25.01.2023 | PUFFER | |
| 12 | 02.02.2023 | Guest Lecture: Linking DBD & Survey data | Johannes Breuer |
| 13 | 08.02.2023 | Semesterabschluss & Evaluation | Christoph Adrian |
Agenda
📢️ Organisation & Koordination
Fragen zur DBD-Analyse mit R
Verständnis- & Diskussionsfragen
Ihre Fragen aus MS Teams
Vielen Dank für Ihre Fragen!
In dem Paper wird darüber berichtet, dass der einzige direkte Weg der Monetarisierung auf TikTok (und auf Douyin) die virtuelle Währung bzw. die virtuellen Geschenke sind. In China ist diese Art des Geschäftsmodell bereits eine sehr etablierte Form der Zahlung, bei uns jedoch noch nicht. Ist es denkbar, dass dieser Trend auch bei uns populär wird?
In dem Paper wird berichtet, dass TikTok teilweise transparenter als andere nicht-asiatischen Plattformen ist. Was genau tut TikTok dafür um diese transparenz zu schaffen?
In Indien ist TikTok bereits verboten. Auch die USA und Australien drohen mit Maßnahmen gegen TikTok. Was hätte dies für ByteDance zur Folge?
Ist die Walkthrough-Methode eine gängige Methode der Datenerhebung auf TikTok und wie läuft diese genau ab? Gibt es andere Methoden, die vielleicht weniger aufwändig sind?
Let’s discuss
Durch die Ideologie (platform governance) einer Plattform kann es kritisch sein, wenn einzelne Plattformen besonders groß werden. Gleichzeitig ist die Existenz von mehreren kleineren Plattformen ebenfalls kritisch, da sich Nischengruppen bilden würden, die nur eine einzelne Perspektive betrachten. (Vgl. CCP Propaganda )
Was könnte eine Lösung für dieses Problem sein?
Laut dem paper wird durch verschiedene video einstellungen von TikTok bereits content “geshaped”. Sind biases auf TikTok dadurch stärker als bei anderen Plattformen?
Group Activity
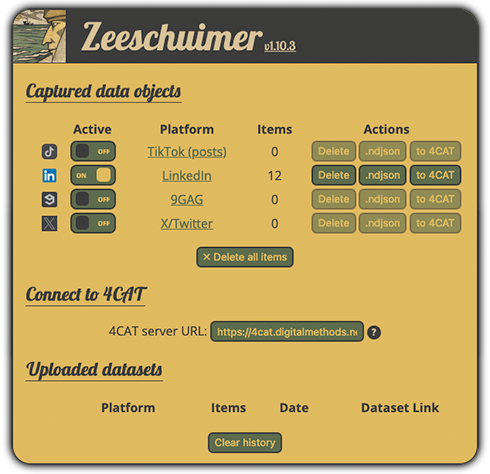
Gruppenarbeit zu Zeeschuimer
What is it & who made it?
Hintergrundinformationen Zeeschuimer (Peeters, 2022)
Browsererweiterung, die während des Besuchs einer Social-Media-Website Daten über die Elemente sammelt, die in der Weboberfläche einer Plattform zu sehen sind
Derzeit werden die folgenden Plattformen unterstützt:
über https://www.tiktok.com
über https://www.instagram.com
Ergänzung zu
4CAT(Peeters & Hagen, 2022)
And now … you: Design your own research
Group activity: Fragestellung ➡️ Datenerhebung ➡️Vergleich
Ziel der Group Activity
Führen Sie in Zweiergruppen eine kleine Case Study durch
Überlegen Sie sich eine Fragestellung, für die Sie mit Hilfe von
Zeeschuimer-Daten erheben und (potentiell) auswerten könnenPräsentieren Sie kurz Ihr Projekt mit Hilfe von maximal 2 Powerpoint-Slides
- Überlegen Sie (in Gruppen), welches Thema Sie untersuchen wollen, d.h.
welchen Begriffen bzw. Hashtags Sie Beiträge zu diesem Thema identifizieren könnten
oder von welchem Account Sie sich die Beiträge anschauen wollen
- Nutzen Sie die
Zeeschuimer-Browsererweiterung und laden Sie (jede Person in der Gruppe) die für Ihre case study relevanten Daten herunter.
- Erkunden Sie Ihren Datensatz und überlegen Sie sich potentielle Auswertungsstrategien.
- Posten Sie eine maximal 2 Folien umfassende Powerpoint-Präsentation auf MS Teams, mit
Ihrer Fragestellung
einer kurzen Beschreibung Ihrer Erhebung
die nächsten (Analyse-)Schritte
Beispielhafte Auswertungen
Im Fokus: Hashtag #statistics
![]()
![]()
![]()
Ein kurzer Überblick
Struktur des TikTok-Datensatzes
Rows: 941
Columns: 24
$ id <chr> "c158c50de9203a700525c2273c722f55", "5794a6967c21834c…
$ thread_id <chr> "c158c50de9203a700525c2273c722f55", "5794a6967c21834c…
$ author <chr> "1e25edc01a1eff924105786baa35cb88", "1e25edc01a1eff92…
$ author_full <chr> "867f5f0cf9b63e68eebb58854d8f779d", "867f5f0cf9b63e68…
$ author_id <chr> "1b94ef47779439aedbf89a519ccb0ac3", "1b94ef47779439ae…
$ author_followers <chr> "34f5624a9f54d961f205fa9ccf2c2816", "34f5624a9f54d961…
$ body <chr> "565707abc618ca27d9f5c9bd718488f0", "63cdbef44fbf560a…
$ timestamp <dttm> 2020-04-09 19:44:39, 2020-05-30 20:28:05, 2020-07-03…
$ unix_timestamp <dbl> 1586461479, 1590870485, 1593811442, 1612846242, 16420…
$ is_duet <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALS…
$ music_name <chr> "SexyBack", "original sound", "original sound", "orig…
$ music_id <dbl> 6.696418e+18, 6.832737e+18, 6.845368e+18, 6.927122e+1…
$ music_url <chr> "https://sf16-ies-music-va.tiktokcdn.com/obj/tos-usea…
$ video_url <chr> "1504eb84f490bc0b7a7245feb5b2e58f", "79c191b9dcea9193…
$ tiktok_url <chr> "6aaa20d1f42837af425dd2656b2d87a7", "d53c488f26b5db40…
$ thumbnail_url <chr> "dd1e26c4dd3b8a8f2d8fa595e7f7af7e", "b99c1df931f7ff61…
$ likes <dbl> 1200000, 910000, 901000, 794300, 740300, 701400, 6490…
$ comments <dbl> 7746, 11900, 3020, 36900, 8179, 8150, 34800, 7592, 28…
$ shares <dbl> 23000, 16600, 1755, 64000, 6397, 1685, 93800, 51300, …
$ plays <dbl> 6700000, 3300000, 5100000, 3800000, 2900000, 2500000,…
$ hashtags <chr> "fyp,love,dating,romance,relationship,crush,people,po…
$ stickers <chr> NA, NA, NA, "that one guy", "Ok…but I guess Timmy is …
$ effects <chr> NA, NA, NA, NA, "Greenscreen", NA, "Disco", NA, "TapT…
$ warning <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…Erstellung eines Korpus
Textverarbeitung mit quanteda (Benoit et al., 2018)
Corpus consisting of 941 documents and 22 docvars.
c158c50de9203a700525c2273c722f55 :
"fyp,love,dating,romance,relationship,crush,people,population..."
5794a6967c21834c4808d8ad0bc13e05 :
"fyp,blacklivesmatter,tiktokpartner,learnontiktok,police,fact..."
abb283c2d6d427232ad29eb35ebf944e :
"skittles,statistics,education,fyp,foryou"
97b1104022105b411a2f9c54ce5740f7 :
"hotguy,itwasntme,turbotaxlivepick6,doritosflatlife,foryou,wa..."
01f2b8936aea8ccc94ac1c8c3a1e7970 :
"timotheechalamet,fyp,foryou,timothee,peach,callmebyyourname,..."
c25da2e0796117dcedb418291a8bdd10 :
"stitch,statistics,staticstics,fyp,foryoupage,trending"
[ reached max_ndoc ... 935 more documents ]Tokenisierung
Textverarbeitung mit quanteda (Benoit et al., 2018)
tkn <- crp %>%
tokens(remove_punct = TRUE,
remove_symbols = TRUE,
remove_url = TRUE,
remove_separators = TRUE)
tknTokens consisting of 941 documents and 22 docvars.
c158c50de9203a700525c2273c722f55 :
[1] "fyp" "love" "dating" "romance" "relationship"
[6] "crush" "people" "population" "world" "math"
[11] "stats" "statistics"
5794a6967c21834c4808d8ad0bc13e05 :
[1] "fyp" "blacklivesmatter" "tiktokpartner" "learnontiktok"
[5] "police" "facts" "fact" "statistics"
[9] "usa"
abb283c2d6d427232ad29eb35ebf944e :
[1] "skittles" "statistics" "education" "fyp" "foryou"
97b1104022105b411a2f9c54ce5740f7 :
[1] "hotguy" "itwasntme" "turbotaxlivepick6"
[4] "doritosflatlife" "foryou" "wap"
[7] "statistics" "fyp" "foryoupage"
[10] "wap"
01f2b8936aea8ccc94ac1c8c3a1e7970 :
[1] "timotheechalamet" "fyp" "foryou" "timothee"
[5] "peach" "callmebyyourname" "statistics"
c25da2e0796117dcedb418291a8bdd10 :
[1] "stitch" "statistics" "staticstics" "fyp" "foryoupage"
[6] "trending"
[ reached max_ndoc ... 935 more documents ]Erstellung einer Document-Feature-Matrix [DFM]
Textverarbeitung mit quanteda (Benoit et al., 2018)
Document-feature matrix of: 941 documents, 2,940 features (99.71% sparse) and 22 docvars.
features
docs fyp love dating romance relationship crush
c158c50de9203a700525c2273c722f55 1 1 1 1 1 1
5794a6967c21834c4808d8ad0bc13e05 1 0 0 0 0 0
abb283c2d6d427232ad29eb35ebf944e 1 0 0 0 0 0
97b1104022105b411a2f9c54ce5740f7 1 0 0 0 0 0
01f2b8936aea8ccc94ac1c8c3a1e7970 1 0 0 0 0 0
c25da2e0796117dcedb418291a8bdd10 1 0 0 0 0 0
features
docs people population world math
c158c50de9203a700525c2273c722f55 1 1 1 1
5794a6967c21834c4808d8ad0bc13e05 0 0 0 0
abb283c2d6d427232ad29eb35ebf944e 0 0 0 0
97b1104022105b411a2f9c54ce5740f7 0 0 0 0
01f2b8936aea8ccc94ac1c8c3a1e7970 0 0 0 0
c25da2e0796117dcedb418291a8bdd10 0 0 0 0
[ reached max_ndoc ... 935 more documents, reached max_nfeat ... 2,930 more features ]Welche Hashtags werden genutzt?
Textvisualisierung mit quanteda.textplots
