Text as data
Digital behavioral data - Extra session
14.12.2022
Nicht neu, aber andere Dimension
Das Phänomen Text as data
Lange Tradition der Text- und Inhaltsanalyse (besonders in der Kommunikationswissenschaft)
Neue Chancen & Herausforderungen durch explosionsartige Vergrößerung des (Text-)Datenaufkommen in den letzten Jahren (Websites, Plattformen & Digitalisierung)

Neue Quellen, Neue Methoden, neue Möglichkeiten
Verschiedene Textgrundlagen als Beispiel

Possibilities over possibilities
Überblick über verschiedene Methoden der Textanalyse

Case study: Reviews
🕵️ ⭐⭐⭐⭐⭐
![]()
![]()
![]()
Im Fokus: 💊 Diätpillen
Hintergrund
- Reviews von fünf “Diätpillen”
- Automatisch Scraping via eigener R-Funktion
- Datensatz mit knapp über 2000 Reviews (ohne Bereinigung)
- Exemplarische Darstellung folgender Schritte:
Text-Processing
Sentiment-Analyse
Topic Modeling


Anzahl der Reviews nach Produkt im Zeitverlauf
Kennenlernen des Datensatzes

Bewertungen der Produkte: Absolute Zahlen
Kennenlernen des Datensatzes

Bewertungen der Produkte: Kummulierte Anteile
Kennenlernen des Datensatzes

☕ Kursevaluation
Bitte nehmen Sie über den QR Code oder folgenden Link an der Evaluation teil:
Losung: QNWVC

Vom Korpus bis zum Model
Prozess der Textverarbeitung
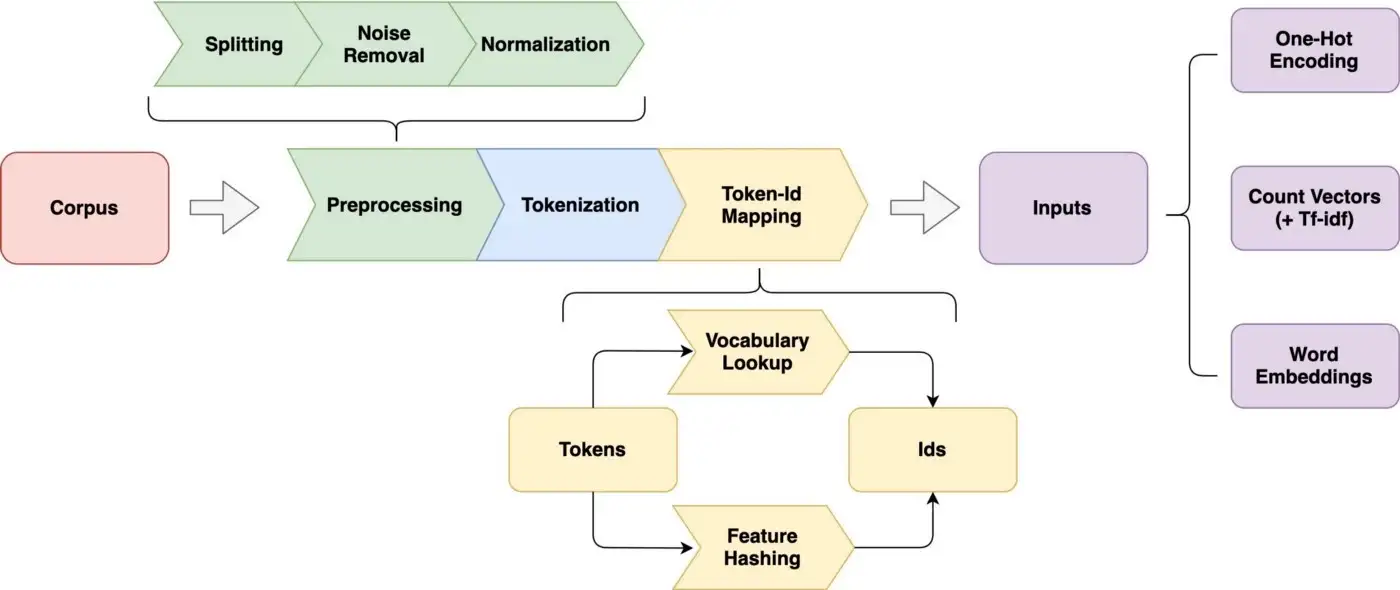
Von BOW zu DFM
Bag-of-words (BOW) und Document-Feature-Matrix (DFM)

Erste Ergebnisse

Structual Topic Modeling im Fokus
Idee und Hintergrund von STM

Welches K?

Kombination aus Kohärenz & Exklusivität

Prevalence der Themen

Literatur
Salganik, M. J. (2018). Bit by bit: Social research in the digital age. Princeton University Press.