| Session | Datum | Topic | Presenter |
|---|---|---|---|
| 📂 Block 1 | Introduction | ||
| 1 | 23.10.2024 | Kick-Off | Christoph Adrian |
| 2 | 30.10.2024 | DBD: Overview & Introduction | Christoph Adrian |
| 3 | 06.11.2024 | 🔨 Introduction to working with R | Christoph Adrian |
| 📂 Block 2 | Theoretical Background: Twitch & TV Election Debates | ||
| 4 | 13.11.2024 | 📚 Twitch-Nutzung im Fokus | Student groups |
| 5 | 20.11.2024 | 📚 (Wirkungs-)Effekte von Twitch & TV-Debatten | Student groups |
| 6 | 27.11.2024 | 📚 Politische Debatten & Social Media | Student groups |
| 📂 Block 3 | Method: Natural Language Processing | ||
| 7 | 04.12.2024 | 🔨 Text as data I: Introduction | Christoph Adrian |
| 8 | 11.12.2024 | 🔨 Text as data II: Advanced Methods | Christoph Adrian |
| 9 | 18.12.2024 | 🔨 Advanced Method I: Topic Modeling | Christoph Adrian |
| No lecture | 🎄Christmas Break | ||
| 10 | 08.01.2025 | 🔨 Advanced Method II: Machine Learning | Christoph Adrian |
| 📂 Block 4 | Project Work | ||
| 11 | 15.01.2025 | 🔨 Project work | Student groups |
| 12 | 22.01.2025 | 🔨 Project work | Student groups |
| 13 | 29.01.2025 | 📊 Project Presentation I | Student groups (TBD) |
| 14 | 05.02.2025 | 📊 Project Presentation & 🏁 Evaluation | Studentds (TBD) & Christoph Adrian |
🔨 Topic Modeling
Session 09
18.12.2024
Seminarplan
Agenda
Eure Meinung ist gefragt!
Bitte nehmt an der kurzen Evaluation teil
Bitte nehmen Sie über den QR Code oder folgenden Link an der Evaluation teil:
- https://eva.fau.de/
- Losung: QNALW
05:00
Topic Modeling mit stm
Eine kurze, möglichst umfangreiche, aber unvollständige Einführung
Quick reminder & preview
Rekapitulation der letzten Sitzung
- Topic Modeling ist ein Verfahren des unüberwachten maschinellen Lernens, das sich zur Exploration und Deskription großer Textmengen eignet um
- unbekannte, latente Themen auf Basis von häufig gemeinsam auftretenden (Clustern an) Wörtern in Dokumenten zu identifizieren
Heutiger Fokus: Umsetzung zentraler Schritte
- Preprocessing
- Modell-Einstellung
- Analyse & Interpretation
- Valdierung
Welche Preprocessing-Schritte sind notwendig?
Umsetzung zentraler Schritte: 1.Preprocessing
- Verschiedene Verfahren möglich bzw. empfohlen (z.B. Denny & Spirling, 2018; Maier et al., 2020)
- Verwendung der empfohlenen Schritte nach Maier et al. (2018):
- ✅ Deduplication;
- ✅ Tokenization;
- ✅ Transform all characters to lowercase;
- 🏗️ Remove punctuation & special characters;
- ⚠️ Create/remove custom Ngrams/stopwords;
- ✅ Term unification (lemmatization)
- 🏗️ Relative Pruning
Von spacyr zu Tokens
Umsetzung zentraler Schritte: 1.Preprocessing
# spacyr-Korpus zu Tokens
chat_spacyr_toks <- chats_spacyr %>%
as.tokens(
use_lemma = TRUE
) %>%
tokens(
remove_punct = TRUE,
remove_symbols = TRUE,
remove_numbers = FALSE,
remove_url = FALSE,
split_hyphens = FALSE,
split_tags = FALSE,
) %>%
tokens_remove(
pattern = stopwords("en")
) %>%
tokens_ngrams(n = 1:3)
# Output
chat_spacyr_toksTokens consisting of 913,245 documents.
dc03b89a-722d-4eaa-a895-736533a68aca :
[1] "60fps" "LETSGO" "60fps" "letsgo" "60fps"
[6] "letsgo" "60fps" "letsgo" "60fps_LETSGO" "LETSGO_60fps"
[11] "60fps_letsgo" "letsgo_60fps"
[ ... and 9 more ]
6be50e12-2fd5-436f-b253-b2358b618380 :
[1] "captain" "o" "captain"
[4] "captain_o" "o_captain" "captain_o_captain"
f5e41904-7f01-4f03-ad6c-2c0f07d70ed0 :
[1] "wokege" "right" "time"
[4] "wokege_right" "right_time" "wokege_right_time"
92dc6519-eb54-4c18-abef-27201314b22f :
[1] "GECKW" "BITCH" "GECKIN"
[4] "GECKW" "GECKW_BITCH" "BITCH_GECKIN"
[7] "GECKIN_GECKW" "GECKW_BITCH_GECKIN" "BITCH_GECKIN_GECKW"
92055088-7067-48c0-aa11-9c6103bdf4c4 :
[1] "YOUCANT" "bring" "back"
[4] "30FPS" "Cinema" "YOUCANT_bring"
[7] "bring_back" "back_30FPS" "30FPS_Cinema"
[10] "YOUCANT_bring_back" "bring_back_30FPS" "back_30FPS_Cinema"
03ad4706-aa67-4ddc-a1e4-6f8ca981778e :
[1] "time" "Wokege" "time_Wokege"
[ reached max_ndoc ... 913,239 more documents ]Wenn die Bereinigung zu gut funktioniert …
1.Preprocessing: Herausforderungen durch leere Nachrichten
- Analysen des
stmTopic Models nutzen Bezüge auf die Stammdaten ➜ Fälle von Modell und Stammdaten müssen übereinstimmen - Probleme:
- Durch Tokenisierung & Pruning können “leere” Chatnachrichten entstehen
- Diese leeren Nachrichten werden bei Schätzung nicht berücksichtigt
- Lösung:
- (Mehrfache) Identifikation & Ausschluss von leeren Nachrichten
Prüfen ➜ Erweitern ➜ Filtern
1.Preprocessing: Herausforderungen bei der Tokenisierung
# Get document names
original_docnames <- chats$message_id
token_docnames <- docnames(chat_spacyr_toks)
# Identify & exclude missing documents
missing_docs <- setdiff(
original_docnames,
token_docnames)
chats_filtered <- chats %>%
filter(!message_id %in% missing_docs)
# Add docvars
docvars(chat_spacyr_toks) <- chats_filtered
# Subset tokens based on docvars
majority_report_chat_toks <- tokens_subset(
chat_spacyr_toks,
streamer == "the_majority_report")
# Output
majority_report_chat_toksTokens consisting of 24,708 documents and 33 docvars.
ChwKGkNJR2poT3pVdVlnREZha1FyUVlkblNrWS1B :
[1] "Donnie" "say" "sperm" "Donnie_say"
[5] "say_sperm" "Donnie_say_sperm"
ChwKGkNLbXd3LXpVdVlnREZWd0wxZ0FkYW9FSWdB :
[1] "wait" "drag" "queen" "Susan"
[5] "chat" "wait_drag" "drag_queen" "queen_Susan"
[9] "Susan_chat" "wait_drag_queen" "drag_queen_Susan" "queen_Susan_chat"
ChwKGkNKR1RsdV9VdVlnREZkNFhyUVlkZ2d3Tk5n :
[1] "person" "turqouise"
[3] "waving::planet" "orange"
[5] "purple" "ring"
[7] "person_turqouise" "turqouise_waving::planet"
[9] "waving::planet_orange" "orange_purple"
[11] "purple_ring" "person_turqouise_waving::planet"
[ ... and 3 more ]
ChwKGkNOQ3kxUExVdVlnREZVS1k1UWNkQ0t3Mlhn :
[1] "re" "need" "link" "re_need" "need_link"
[6] "re_need_link"
ChwKGkNPcW5fZkxVdVlnREZlSFJsQWtkbThZaUtR :
[1] "praise" "god" "praise_god"
ChwKGkNNUHZzdlhVdVlnREZha1FyUVlkblNrWS1B :
[1] "STREAM" "start" "15" "STREAM_start"
[5] "start_15" "STREAM_start_15"
[ reached max_ndoc ... 24,702 more documents ]Transformation in eine DFM
Umsetzung zentraler Schritte: 1.Preprocessing
# Convert to DFM
majority_report_chat_dfm <- majority_report_chat_toks %>%
dfm()
# Output
majority_report_chat_dfm %>%
print(max_nfeat = 4)Document-feature matrix of: 24,708 documents, 84,931 features (>99.99% sparse) and 33 docvars.
features
docs donnie say sperm donnie_say
ChwKGkNJR2poT3pVdVlnREZha1FyUVlkblNrWS1B 1 1 1 1
ChwKGkNLbXd3LXpVdVlnREZWd0wxZ0FkYW9FSWdB 0 0 0 0
ChwKGkNKR1RsdV9VdVlnREZkNFhyUVlkZ2d3Tk5n 0 0 0 0
ChwKGkNOQ3kxUExVdVlnREZVS1k1UWNkQ0t3Mlhn 0 0 0 0
ChwKGkNPcW5fZkxVdVlnREZlSFJsQWtkbThZaUtR 0 0 0 0
ChwKGkNNUHZzdlhVdVlnREZha1FyUVlkblNrWS1B 0 0 0 0
[ reached max_ndoc ... 24,702 more documents, reached max_nfeat ... 84,927 more features ]Pruning der DFM
Umsetzung zentraler Schritte: 1.Preprocessing
# Pruning
majority_report_chat_trim <- majority_report_chat_dfm %>%
dfm_trim(
min_docfreq = 50/nrow(chats),
max_docfreq = 0.99,
docfreq_type = "prop"
)
# Output
majority_report_chat_trim %>%
print(max_nfeat = 4)Document-feature matrix of: 24,708 documents, 11,035 features (99.97% sparse) and 33 docvars.
features
docs donnie say sperm wait
ChwKGkNJR2poT3pVdVlnREZha1FyUVlkblNrWS1B 1 1 1 0
ChwKGkNLbXd3LXpVdVlnREZWd0wxZ0FkYW9FSWdB 0 0 0 1
ChwKGkNKR1RsdV9VdVlnREZkNFhyUVlkZ2d3Tk5n 0 0 0 0
ChwKGkNOQ3kxUExVdVlnREZVS1k1UWNkQ0t3Mlhn 0 0 0 0
ChwKGkNPcW5fZkxVdVlnREZlSFJsQWtkbThZaUtR 0 0 0 0
ChwKGkNNUHZzdlhVdVlnREZha1FyUVlkblNrWS1B 0 0 0 0
[ reached max_ndoc ... 24,702 more documents, reached max_nfeat ... 11,031 more features ]Konvertierung für stm Topic Modeling
Umsetzung zentraler Schritte: 1.Preprocessing
Entscheidungen über Entscheidungen
Umsetzung zentraler Schritte: 2.Modell-Einstellung
- Welches Verfahren bzw. welchen Algorithmus wählen?
- Matrixfactorisierung (LSA, NMF)
- Probabilistische Modelle (LDA, CTM, STM)
- Deep Learning (BERT, GPT-2)
- Welche Parameter bzw. Hyperparameter sind wie zu berücksichtigen?
- Anzahl der Iterationen
- Seed für Reproduzierbarkeit
- Initialisierungsmethode
- Wie viele Themen (
K) sollen identifiziert werden?
Die Suche nach der optimalen Anzahl von Themen
Umsetzung zentraler Schritte: 2.Modell-Einstellung
- Wahl von
K(ob das Modell angewiesen wird, 5, 15 oder 100 Themen zu identifizieren) hat erheblichen Einfluss auf die Ergebnisse:- je kleiner
K, desto breiter und allgemeiner sind die Themen - je größer
K, desto feinkörniger und spezifischer, aber auch überlappender und weniger exklusiv sind
- je kleiner
- keine allgemeingültige Lösung für die Bestimmung, da abhängig von vielen Faktoren, z.B.
- als was Themen im Kontext der Analyse theoretisch definiert sind
- die Beschaffenheit des Korpus
How to find K
2.Modell-Einstellung: Suche nach dem Modell mit dem optimalen K
- Das
stm-Paket (v1.3.7, Roberts et al., 2019) bietet zwei integrierte Lösungen, um das optimaleKzu finden:searchK()Funktion- Verwendung des Argumentes
K = 0bei der Schätzung des Modells - Empfehlung: (Manuelles) Training und Bewertung!
- Entscheidung basiert u.a. auf:
- Stastischem Fit (z.B. Coherence, Perplexity)
- Interpretierbarkeit (z.B. Top Features, Top Documents)
- Rank-1-Metrik (z.B. Häufigkeit bestimmter Themen)
Manuell trainiert & exploriert
Umsetzung zentraler Schritte: 2.Modell-Einstellung
# Set up parallel processing using furrr
future::plan(future::multisession())
# Estimate models
stm_search <- tibble(
k = seq(from = 4, to = 20, by = 2)
) %>%
mutate(
mdl = furrr::future_map(
k,
~stm::stm(
documents = majority_report_chat_stm$documents,
vocab = majority_report_chat_stm$vocab,
prevalence =~ platform + debate + message_during_debate,
K = .,
seed = 42,
max.em.its = 1000,
data = majority_report_chat_stm$meta,
init.type = "Spectral",
verbose = TRUE),
.options = furrr::furrr_options(seed = 42)
)
)[[1]]
A topic model with 4 topics, 23060 documents and a 11035 word dictionary.
[[2]]
A topic model with 6 topics, 23060 documents and a 11035 word dictionary.
[[3]]
A topic model with 8 topics, 23060 documents and a 11035 word dictionary.
[[4]]
A topic model with 10 topics, 23060 documents and a 11035 word dictionary.
[[5]]
A topic model with 12 topics, 23060 documents and a 11035 word dictionary.
[[6]]
A topic model with 14 topics, 23060 documents and a 11035 word dictionary.
[[7]]
A topic model with 16 topics, 23060 documents and a 11035 word dictionary.
[[8]]
A topic model with 18 topics, 23060 documents and a 11035 word dictionary.
[[9]]
A topic model with 20 topics, 23060 documents and a 11035 word dictionary.Berechnung der Modell-Diagnostik
2.Modell-Einstellung: Suche nach dem Modell mit dem optimalen K
# Create heldout
heldout <- make.heldout(
majority_report_chat_stm$documents,
majority_report_chat_stm$vocab,
seed = 42)
# Create model diagnostics
stm_results <- stm_search %>%
mutate(
exclusivity = map(mdl, exclusivity),
semantic_coherence = map(mdl, semanticCoherence, majority_report_chat_stm$documents),
eval_heldout = map(mdl, eval.heldout, heldout$missing),
residual = map(mdl, checkResiduals, majority_report_chat_stm$documents),
bound = map_dbl(mdl, function(x) max(x$convergence$bound)),
lfact = map_dbl(mdl, function(x) lfactorial(x$settings$dim$K)),
lbound = bound + lfact,
iterations = map_dbl(mdl, function(x) length(x$convergence$bound))
)Überblick über Modell-Diagnostik
2.Modell-Einstellung: Suche nach dem Modell mit dem optimalen K
# A tibble: 9 × 10
k mdl exclusivity semantic_coherence eval_heldout residual bound
<dbl> <list> <list> <list> <list> <list> <dbl>
1 4 <STM> <dbl [4]> <dbl [4]> <named list> <named list> -745060.
2 6 <STM> <dbl [6]> <dbl [6]> <named list> <named list> -739258.
3 8 <STM> <dbl [8]> <dbl [8]> <named list> <named list> -734111.
4 10 <STM> <dbl [10]> <dbl [10]> <named list> <named list> -729647.
5 12 <STM> <dbl [12]> <dbl [12]> <named list> <named list> -725092.
6 14 <STM> <dbl [14]> <dbl [14]> <named list> <named list> -723050.
7 16 <STM> <dbl [16]> <dbl [16]> <named list> <named list> -722053.
8 18 <STM> <dbl [18]> <dbl [18]> <named list> <named list> -718276.
9 20 <STM> <dbl [20]> <dbl [20]> <named list> <named list> -719322.
# ℹ 3 more variables: lfact <dbl>, lbound <dbl>, iterations <dbl>Kurzer Crashkurs
Überblick über die verschiedenen Evaluationskritierien
Held-Out Likelihoodmisst, wie gut ein Modell ungesehene Daten vorhersagt (ABER: kein allgemeingültiger Schwellenwert, nur Vergleich identischer Daten). Höhere Werte weisen auf eine bessere Vorhersageleistung hin.Lower boundist eine Annäherung an die Log-Likelihood des Modells. Ein höherer Wert deutet auf eine bessere Anpassung an die Daten hin.Residuengeben die Differenz zwischen den beobachteten und den vorhergesagten Werten an. Kleinere Residuen deuten auf eine bessere Modellanpassung hin. Im Idealfall sollten die Residuen so klein wie möglich sein.Semantische Kohärenzmisst, wie semantisch verwandt die wichtigsten Wörter eines Themas sind, wobei höhere Werte auf kohärentere Themen hinweisen.
Vergleich des statistischen Fits
2.Modell-Einstellung: Suche nach dem Modell mit dem optimalen K
Expand for full code
# Visualize
stm_results %>%
transmute(
k,
`Lower bound` = lbound,
Residuals = map_dbl(residual, "dispersion"),
`Semantic coherence` = map_dbl(semantic_coherence, mean),
`Held-out likelihood` = map_dbl(eval_heldout, "expected.heldout")) %>%
gather(Metric, Value, -k) %>%
ggplot(aes(k, Value, color = Metric)) +
geom_line(size = 1.5, alpha = 0.7, show.legend = FALSE) +
geom_point(size = 3) +
scale_x_continuous(breaks = seq(from = 4, to = 20, by = 2)) +
facet_wrap(~Metric, scales = "free_y") +
labs(x = "K (Anzahl der Themen)",
y = NULL,
title = "Statistischer Fit der STM-Modelle",
subtitle = "Kohärenz sollte hoch, Residuen niedrig sein"
) +
theme_pubr()Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.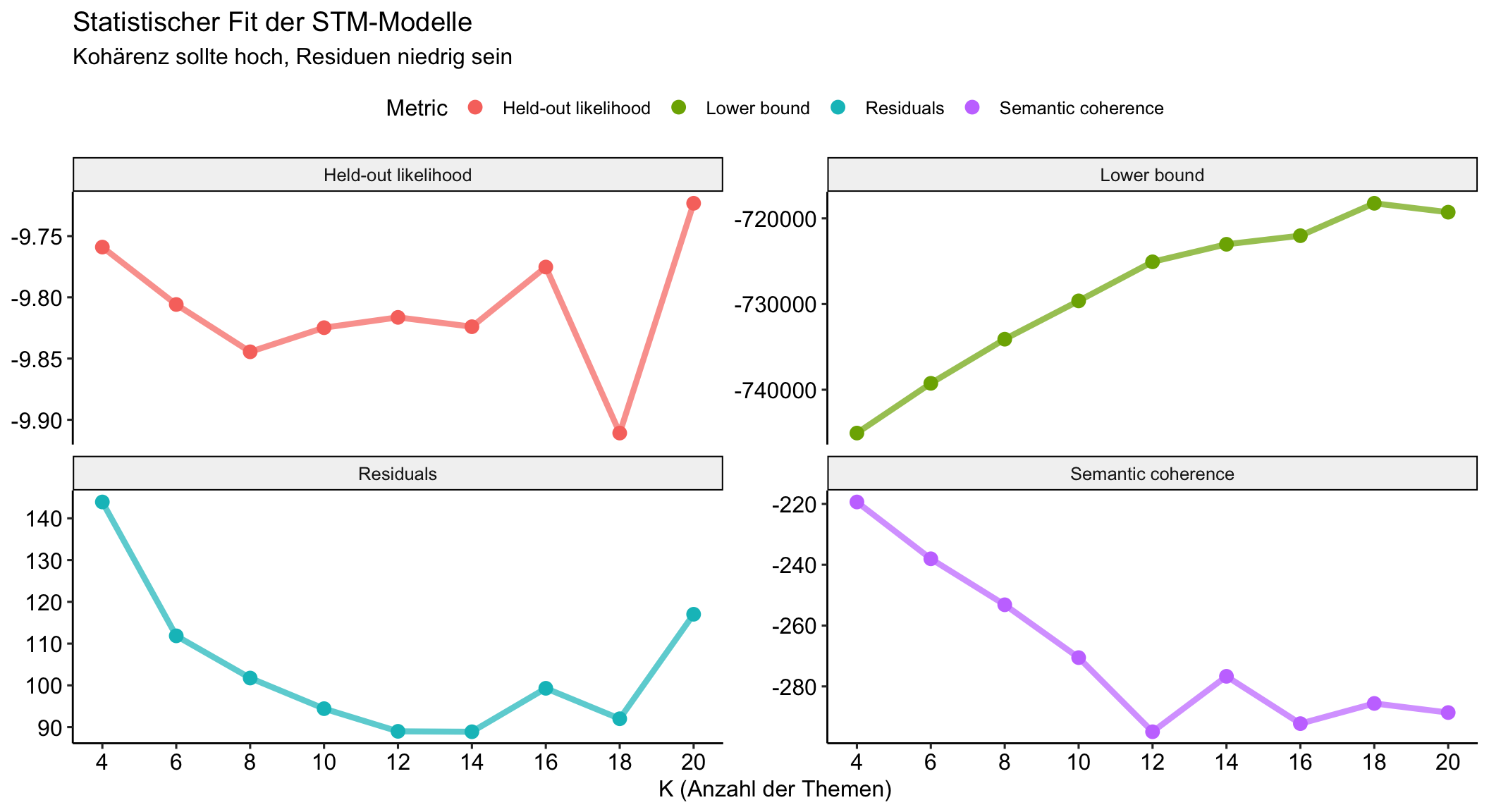
Hohe Kohärenz bei hoher Exklusivität
2.Modell-Einstellung: Suche nach dem Modell mit dem optimalen K
Expand for full code
# Models for comparison
models_for_comparison = c(12, 14, 18)
# Create figures
fig_excl <- stm_results %>%
# Edit data
select(k, exclusivity, semantic_coherence) %>%
filter(k %in% models_for_comparison) %>%
unnest(cols = c(exclusivity, semantic_coherence)) %>%
mutate(k = as.factor(k)) %>%
# Build graph
ggplot(aes(semantic_coherence, exclusivity, color = k)) +
geom_point(size = 2, alpha = 0.7) +
labs(
x = "Semantic coherence",
y = "Exclusivity"
# title = "Comparing exclusivity and semantic coherence",
# subtitle = "Models with fewer topics have higher semantic coherence for more topics, but lower exclusivity"
) +
theme_pubr()
# Create plotly
fig_excl %>% plotly::ggplotly()Extraktion der Beta- & Gamma-Matrix
2.Modell-Einstellung: Interpretierbarkeit der Top Features
# A tibble: 322,840 × 3
document topic gamma
<chr> <int> <dbl>
1 ChwKGkNJR2poT3pVdVlnREZha1FyUVlkblNrWS1B 1 0.0261
2 ChwKGkNLbXd3LXpVdVlnREZWd0wxZ0FkYW9FSWdB 1 0.0265
3 ChwKGkNKR1RsdV9VdVlnREZkNFhyUVlkZ2d3Tk5n 1 0.0123
4 ChwKGkNOQ3kxUExVdVlnREZVS1k1UWNkQ0t3Mlhn 1 0.0200
5 ChwKGkNPcW5fZkxVdVlnREZlSFJsQWtkbThZaUtR 1 0.0232
6 ChwKGkNNUHZzdlhVdVlnREZha1FyUVlkblNrWS1B 1 0.0236
7 ChwKGkNLT1JuX2pVdVlnREZZX0FsQWtkcEw4Wmd3 1 0.434
8 ChwKGkNLRElvZmpVdVlnREZaWExGZ2tkTy1ZSXVR 1 0.0118
9 ChwKGkNNblNqZm5VdVlnREZhX0l3Z1FkZUg0bHZn 1 0.0356
10 ChwKGkNMeUkyUHZVdVlnREZXQUhyUVlkTUJvZ193 1 0.00307
# ℹ 322,830 more rowsExtraktion der Top Features nach Thema
2.Modell-Einstellung: Interpretierbarkeit der Top Features
# Create gamma data
top_gamma_k14 <- tpm_k14 %>%
tidy(matrix = "gamma") %>%
dplyr::group_by(topic) %>%
dplyr::summarise(
gamma = mean(gamma),
.groups = "drop") %>%
dplyr::arrange(desc(gamma))
# Create beta data
top_beta_k14 <- tpm_k14 %>%
tidytext::tidy(.) %>%
dplyr::group_by(topic) %>%
dplyr::arrange(-beta) %>%
dplyr::top_n(7, wt = beta) %>%
dplyr::select(topic, term) %>%
dplyr::summarise(
terms_beta = toString(term),
.groups = "drop")Beschreiben Top Features ein Topic sinnvoll?
2.Modell-Einstellung: Interpretierbarkeit der Top Features
| topic | terms_beta | gamma |
|---|---|---|
| Topic 8 | make, 's, lul, emma, fuchsia, liar, kekl | 0.115 |
| Topic 7 | good, right, now, yes, plan, lie, bad | 0.113 |
| Topic 12 | kamala, want, biden, eat, take, vote, god | 0.109 |
| Topic 5 | get, s, wow, mad, omg, thank, nice | 0.101 |
| Topic 4 | lmao, omegalul, red, green, orange, baby, kekw | 0.079 |
| Topic 3 | time, sam, love, man, need, old, big | 0.075 |
| Topic 11 | say, oh, ..., know, look, shit, yeah | 0.075 |
| Topic 1 | go, like, fact, debate, look, check, keep | 0.058 |
| Topic 13 | trump, just, donald, lose, racist, win, can | 0.056 |
| Topic 9 | lol, one, give, ...., wtf, china, okay | 0.051 |
| Topic 6 | people, think, go, back, work, try, change | 0.050 |
| Topic 10 | let, talk, ’s, can, like, sound, see | 0.045 |
| Topic 2 | stop, start, please, israel, use, laugh, agree | 0.039 |
| Topic 14 | face, guy, don, bring, real, country, rolling_on_the_floor_laughe | 0.034 |
Extraktion & Zusammenführung der Daten
2.Modell-Einstellung: Interpretierbarkeit der Top Documents
# Prepare for merging
topic_gammas_k14 <- tpm_k14 %>%
tidy(matrix = "gamma") %>%
dplyr::group_by(document) %>%
tidyr::pivot_wider(
id_cols = document,
names_from = "topic",
names_prefix = "gamma_topic_",
values_from = "gamma")
gammas_k14 <- tpm_k14 %>%
tidytext::tidy(matrix = "gamma") %>%
dplyr::group_by(document) %>%
dplyr::slice_max(gamma) %>%
dplyr::mutate(
main_topic = ifelse(
gamma > 0.5, topic, NA)) %>%
rename(
top_topic = topic,
top_gamma = gamma) %>%
ungroup() %>%
left_join(.,
topic_gammas_k14,
by = join_by(document))# Identify empty documents
empty_docs <- Matrix::rowSums(
as(majority_report_chat_trim, "Matrix")) == 0
empty_docs_ids <- majority_report_chat_trim@docvars$docname[empty_docs]
# Merge with original data
chats_topics <- chats_filtered %>%
filter(!(message_id %in% empty_docs_ids)) %>%
filter(streamer == "the_majority_report") %>%
bind_cols(gammas_k14) %>%
select(-document)Angereicherter Datensatz
2.Modell-Einstellung: Interpretierbarkeit der Top Documents
Rows: 23,060
Columns: 50
$ streamer <chr> "the_majority_report", "the_majority_report", "t…
$ url <chr> "https://www.youtube.com/watch?v=lzobJil9Sgc", "…
$ platform <chr> "youtube", "youtube", "youtube", "youtube", "you…
$ debate <chr> "presidential", "presidential", "presidential", …
$ user_name <chr> "Scott Plant", "Rebecca W", "Galactic News Netwo…
$ user_id <chr> "UC4mxlnk193JrXVAp6K-vEpQ", "UCeenHJ1v62biyOyKwL…
$ user_display_name <chr> "Scott Plant", "Rebecca W", "Galactic News Netwo…
$ user_badges <list> [], [], [], [], [], [], [], [], [], [], [], [],…
$ message_timestamp <dbl> -152, -151, -145, -138, -137, -132, -126, -126, …
$ message_id <chr> "ChwKGkNJR2poT3pVdVlnREZha1FyUVlkblNrWS1B", "Chw…
$ message_type <chr> "text_message", "text_message", "text_message", …
$ message_content <chr> "Donnie will say, \"That is my own sperm.\"", "w…
$ message_emotes <list> [], [], [["UCkszU2WH9gy1mb0dV-11UJg/ssIfY7OFG5O…
$ message_length <int> 40, 45, 52, 38, 10, 32, 8, 14, 2, 90, 20, 36, 20…
$ message_timecode <Period> -2M -32S, -2M -31S, -2M -25S, -2M -18S, -2M -…
$ message_time <chr> "23:57:28", "23:57:29", "23:57:35", "23:57:42", …
$ message_during_debate <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_has_badge <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_premium <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_subscriber <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_turbo <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_moderator <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_partner <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_subgifter <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_broadcaster <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_vip <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_twitchdj <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_founder <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_staff <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_game_dev <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_is_ambassador <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_no_audio <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ user_no_video <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ top_topic <int> 11, 7, 4, 3, 4, 3, 1, 4, 9, 4, 8, 3, 1, 1, 3, 13…
$ top_gamma <dbl> 0.4435422, 0.3412468, 0.7627751, 0.5663056, 0.46…
$ main_topic <int> NA, NA, 4, 3, NA, NA, NA, 4, NA, 4, NA, NA, NA, …
$ gamma_topic_1 <dbl> 0.026098022, 0.026450828, 0.012260893, 0.0200424…
$ gamma_topic_2 <dbl> 0.014058480, 0.016014175, 0.006519458, 0.1322111…
$ gamma_topic_3 <dbl> 0.043655546, 0.066001729, 0.018185091, 0.5663056…
$ gamma_topic_4 <dbl> 0.03876696, 0.14976529, 0.76277514, 0.03011074, …
$ gamma_topic_5 <dbl> 0.186801763, 0.043801244, 0.020095565, 0.0373451…
$ gamma_topic_6 <dbl> 0.021470740, 0.024622665, 0.009041711, 0.0174135…
$ gamma_topic_7 <dbl> 0.036282513, 0.341246826, 0.017882159, 0.0289225…
$ gamma_topic_8 <dbl> 0.04538521, 0.14311198, 0.06168206, 0.03558740, …
$ gamma_topic_9 <dbl> 0.021910232, 0.023552979, 0.012143933, 0.0165138…
$ gamma_topic_10 <dbl> 0.020656194, 0.020843309, 0.013562820, 0.0161670…
$ gamma_topic_11 <dbl> 0.443542243, 0.027314995, 0.019249172, 0.0206369…
$ gamma_topic_12 <dbl> 0.044397591, 0.044680183, 0.019709728, 0.0343713…
$ gamma_topic_13 <dbl> 0.027631227, 0.037326873, 0.011473224, 0.0214522…
$ gamma_topic_14 <dbl> 0.029343282, 0.035266919, 0.015419046, 0.0229199…Top Topic im Fokus
2.Modell-Einstellung: Passen Top Document zum Thema?
Expand for full code
| message_id | user_name | message_time | message_content | top_gamma | top_topic |
|---|---|---|---|---|---|
| ChwKGkNKdlRqY1BwdVlnREZRREV3Z1FkV2I4U1hn | David Davis | 01:29:52 | :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: | 0.9628609 | 8 |
| ChwKGkNLMlp3cUxzdVlnREZVN0NsQWtkT0JBRTN3 | Jules Winnfeild 🏳️⚧️ | 01:42:09 | :face-fuchsia-poop-shape::face-fuchsia-poop-shape::face-fuchsia-poop-shape::face-fuchsia-poop-shape::face-fuchsia-poop-shape::face-fuchsia-poop-shape::face-fuchsia-poop-shape: | 0.9583042 | 8 |
| ChwKGkNNclk0dFBZdVlnREZZYWg1UWNkUlhvNVB3 | CanalEduge | 00:14:24 | :face-fuchsia-poop-shape::face-fuchsia-poop-shape::face-fuchsia-poop-shape::face-fuchsia-poop-shape::face-fuchsia-poop-shape: | 0.9437816 | 8 |
| ChwKGkNJaVdpNVBmdVlnREZTV1Q1UWNkUWg0dEJn | Jules Winnfeild 🏳️⚧️ | 00:43:27 | :face-fuchsia-poop-shape::face-fuchsia-poop-shape::face-fuchsia-poop-shape::face-fuchsia-poop-shape: | 0.9315330 | 8 |
| ChwKGkNORG1uTWpvdVlnREZkd3VyUVlkSVFrVU5R | #BobbleHead | 01:25:34 | WORLDSTAR own's the Trademark on the Algorithm that identified all the Pedophiles = Blame T.M.Z. #ReleaseTheBlackBaby | 0.9313871 | 8 |
| ChwKGkNPV09fYmJwdVlnREZXc3ByUVlkbk9Vc3d3 | David Davis | 01:29:26 | :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: :watermelon: | 0.9303014 | 8 |
| ChwKGkNMV244NkRvdVlnREZUMFRyUVlkYmZzUmpB | #BobbleHead | 01:24:12 | WORLDSTAR own's the Trademark on the Algorithm that identified all the Pedophiles = Blame T.M.Z. | 0.9287878 | 8 |
| ChwKGkNLN0N4ZTdldVlnREZWNDZyUVlkRmZJRklR | Corporations8MyBaby | 00:42:10 | :face-fuchsia-tongue-out::face-fuchsia-tongue-out::face-fuchsia-tongue-out::face-fuchsia-tongue-out: | 0.9269656 | 8 |
| 9c014ab4-89a7-4f9d-97c8-be3da2868f58 | nightbot | 00:10:47 | Join the official Majority Report discord community! https://discord.gg/majority | 0.9215614 | 8 |
| fcb53a8b-4b75-4557-b3eb-d273b7069d88 | nightbot | 00:26:14 | Join the official Majority Report discord community! https://discord.gg/majority | 0.9215614 | 8 |
Thema 12 im Fokus
2.Modell-Einstellung: Passen Top Document zum Thema?
Expand for full code
| message_id | user_name | message_time | message_content | top_gamma | top_topic |
|---|---|---|---|---|---|
| ChwKGkNNZXg5LUxxdVlnREZkcVc1UWNkeGpNTDJB | SamSedersLeftTeste | 01:35:27 | The vice president is BLACK BLACK BLACK BLACK BLACK BLACK | 0.9227423 | 12 |
| ChwKGkNNdVU0NTNndVlnREZkNEwxZ0FkbWxFSFN3 | Rilly Kewl | 00:48:18 | Hey Hey Hey Hey SHUT UP:red_exclamation_mark: | 0.9121621 | 12 |
| ChwKGkNJU1BtS0RndVlnREZRREV3Z1FkV2I4U1hn | Rilly Kewl | 00:48:23 | Hey Hey Hey Hey SHUT UP:red_exclamation_mark: | 0.9121621 | 12 |
| ChwKGkNJS1NvcVRndVlnREZRMHUxZ0FkU1FFSzZB | Rilly Kewl | 00:48:31 | Hey Hey Hey Hey SHUT UP:red_exclamation_mark: | 0.9121621 | 12 |
| ChwKGkNLSG9uYUxodVlnREZhY0cxZ0FkSVJjSGdB | Rilly Kewl | 00:52:56 | Hey Hey Hey Hey SHUT UP:red_exclamation_mark: | 0.9121621 | 12 |
| ChwKGkNPbU90YV9odVlnREZWZ3FyUVlkaUpnNUpn | Rilly Kewl | 00:53:23 | Hey Hey Hey Hey SHUT UP:red_exclamation_mark: | 0.9121621 | 12 |
| ChwKGkNLYmxuZjdzdVlnREZiMHUxZ0FkT0owN0h3 | Rilly Kewl | 01:45:21 | Hey Hey Hey Hey SHUT UP:red_exclamation_mark: | 0.9121621 | 12 |
| ChwKGkNLX3F4cl90dVlnREZWbzAxZ0FkdzVFTTR3 | Rilly Kewl | 01:47:38 | Hey Hey Hey Hey SHUT UP:red_exclamation_mark: | 0.9121621 | 12 |
| ChwKGkNOYm1yTVB0dVlnREZWb0gxZ0FkQnF3QWRR | Rilly Kewl | 01:47:46 | Hey Hey Hey Hey SHUT UP:red_exclamation_mark: | 0.9121621 | 12 |
| bad4de96-6c3f-4495-9bd5-da395d9af90b | grandshadowfox | 01:07:37 | Grandshadowfox subscribed with Prime. They've subscribed for 16 months! 15 months | 0.9064436 | 12 |
Thema 4 im Fokus
2.Modell-Einstellung: Passen Top Document zum Thema?
Expand for full code
| message_id | user_name | message_time | message_content | top_gamma | top_topic |
|---|---|---|---|---|---|
| ChwKGkNLX3Z3SzdkdVlnREZhb0NyUVlkVER3aVRn | rhys | 00:35:28 | :text-green-game-over::text-green-game-over::text-green-game-over::text-green-game-over::text-green-game-over::text-green-game-over: | 0.9687024 | 4 |
| ChwKGkNJN1hsSXJudVlnREZWTGNGZ2tkYnFnYmJB | Jules Winnfeild 🏳️⚧️ | 01:18:56 | :fish-orange-wide-eyes::fish-orange-wide-eyes::fish-orange-wide-eyes::fish-orange-wide-eyes::fish-orange-wide-eyes: | 0.9649579 | 4 |
| ChwKGkNJQ3ZzYTdXdVlnREZSek1GZ2tkMndnZ1Bn | fish Monger | 00:04:09 | ideas:finger-red-number-one::finger-red-number-one::finger-red-number-one::finger-red-number-one::finger-red-number-one::finger-red-number-one::finger-red-number-one::finger-red-number-one: | 0.9647715 | 4 |
| ChwKGkNNcmVxb0RmdVlnREZhb0NyUVlkVER3aVRn | rhys | 00:42:48 | :text-green-game-over::text-green-game-over::text-green-game-over::text-green-game-over::text-green-game-over: | 0.9630820 | 4 |
| 32d36382-5eaf-4da6-a2dc-c9683b98162b | nightbot | 00:01:27 | Libertarians, call into the show! 646 257-3920. Phones open after 1pm EST. Download the Majority Report app to IM into the show. Go to JoinTheMajorityReport.com to become a member and help support the show. | 0.9629138 | 4 |
| 4ffbae78-db39-40e9-bcf8-b5c0965fe2a4 | nightbot | 00:09:42 | Libertarians, call into the show! 646 257-3920. Phones open after 1pm EST. Download the Majority Report app to IM into the show. Go to JoinTheMajorityReport.com to become a member and help support the show. | 0.9629138 | 4 |
| a08570c3-f835-4568-9332-b97bf22ee61b | nightbot | 02:01:22 | Libertarians, call into the show! 646 257-3920. Phones open after 1pm EST. Download the Majority Report app to IM into the show. Go to JoinTheMajorityReport.com to become a member and help support the show. | 0.9629138 | 4 |
| 46b82320-e59d-486e-a58f-acf35b03fe4a | nightbot | 02:09:43 | Libertarians, call into the show! 646 257-3920. Phones open after 1pm EST. Download the Majority Report app to IM into the show. Go to JoinTheMajorityReport.com to become a member and help support the show. | 0.9629138 | 4 |
| 191d1514-cc7e-4a65-8c9e-0ce5d28f1a5d | nightbot | 02:22:30 | Libertarians, call into the show! 646 257-3920. Phones open after 1pm EST. Download the Majority Report app to IM into the show. Go to JoinTheMajorityReport.com to become a member and help support the show. | 0.9629138 | 4 |
| ed759097-6071-4394-b810-5adafd52f652 | nightbot | 02:35:23 | Libertarians, call into the show! 646 257-3920. Phones open after 1pm EST. Download the Majority Report app to IM into the show. Go to JoinTheMajorityReport.com to become a member and help support the show. | 0.9629138 | 4 |
Fließender Übergang in die Analyse
Umsetzung zentraler Schritte: 3.Analyse & Interpretation
stm ermöglicht den Einfluss unabhängiger Variablen zu modellieren, genauer auf:
- die Prävalenz von Themen (prevalence-Argument)
- den Inhalt von Themen (content-Argument)
Interpreation:
- Identifikation & Ausschluss von „Background“-Topics
- Identifikation & Labelling von relevanten Topics
- Ggf. Gruppierung in übergreifende Kontexte (z.B. „politische Themen“)
- Nutzung für deskriptive oder inferenzstatistische Verfahren
User mit den meisten Beiträgen zu Thema 4
3.Analyse & Interpretation - Beispiel für deskriptive Verfahren
| user_name | n | prop |
|---|---|---|
| buuuuuuuuuuuuuuuuuuuuuut | 59 | 1.83 |
| sauvignoncitizen | 50 | 1.55 |
| Say What | 49 | 1.52 |
| Jules Winnfeild 🏳️⚧️ | 47 | 1.45 |
| asiak | 46 | 1.42 |
| hardradajm | 40 | 1.24 |
| Bob Carmody | 34 | 1.05 |
| T.R. | 33 | 1.02 |
| maj_k1bbles | 31 | 0.96 |
| ogdimwit | 31 | 0.96 |
Prävalenz vs. Häufigkeit
3.Analyse & Interpretation - Beispiel für deskriptive Verfahren
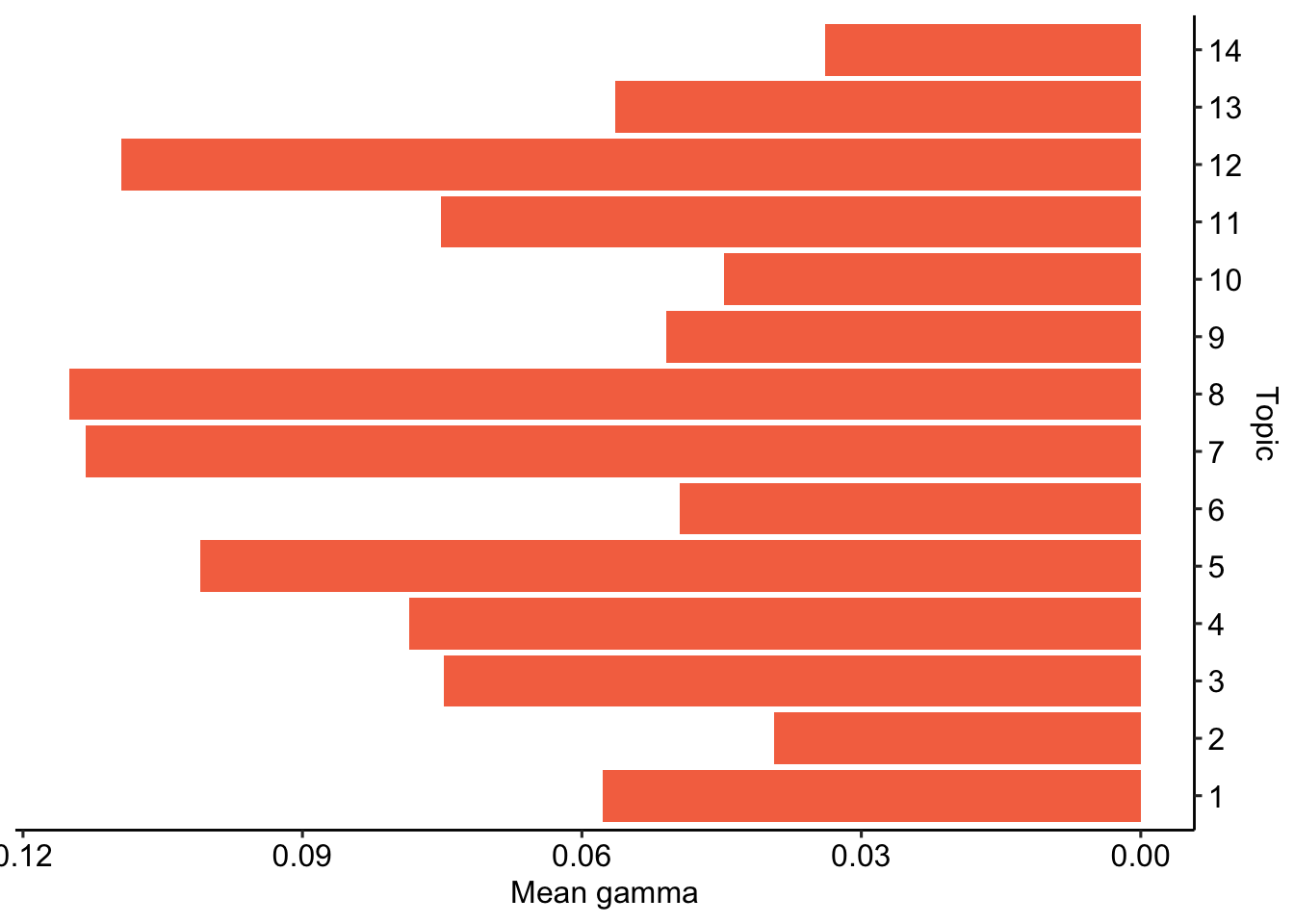
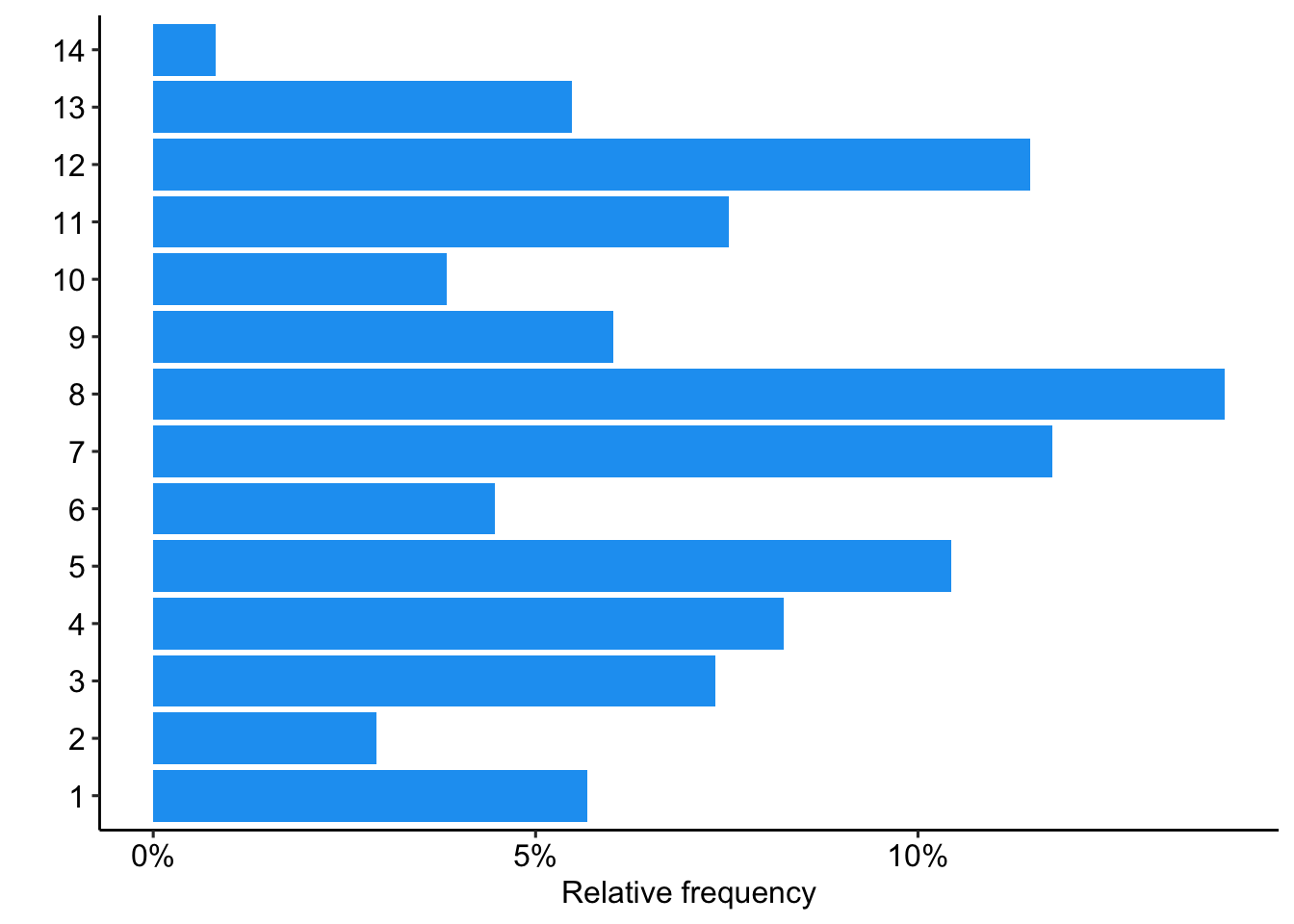
Einfluss von Meta-Variablen
3.Analyse & Interpretation - Beispiel für inferenzstatistische Verfahren
effects <- estimateEffect(
formula =~ platform + debate + message_during_debate,
stmobj = tpm_k14,
metadata = chats_topics)Warning in estimateEffect(formula = ~platform + debate + message_during_debate, : Covariate matrix is singular. See the details of ?estimateEffect() for some common causes.
Adding a small prior 1e-5 for numerical stability.
Call:
estimateEffect(formula = ~platform + debate + message_during_debate,
stmobj = tpm_k14, metadata = chats_topics)
Topic 12:
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.130299 29.076022 0.004 0.99642
platformyoutube -0.044308 29.075963 -0.002 0.99878
debatevice presidential -0.054949 29.075974 -0.002 0.99849
message_during_debate 0.012174 0.004523 2.691 0.00712 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call:
estimateEffect(formula = ~platform + debate + message_during_debate,
stmobj = tpm_k14, metadata = chats_topics)
Topic 8:
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.343159 29.348608 0.012 0.991
platformyoutube -0.253151 29.348565 -0.009 0.993
debatevice presidential -0.233550 29.348558 -0.008 0.994
message_during_debate 0.001028 0.004541 0.226 0.821Shiny-App als Hilfe für die Analyse
Visualisierung mit stminsights (v4.1.0, Schwemmer, 2021)
Die 4 R`s
Umsetzung zentraler Schritte: 4.Validierung
- Reliabilität/Robustheit: Kommen wir mit anderen Instrumenten zu ähnlichen Ergebnissen? (Roberts et al., 2016; Wilkerson & Casas, 2017)
- Reproduzierbarkeit: Können wir mit den gleichen Daten & Instrumenten die Ergebnisse reproduzieren? (Chung-hong Chan et al., 2024)
- Replizierbarkeit: Lassen sich unsere Ergebnisse für andere Daten reproduzieren? (Breuer & Haim, 2024; Long, 2021)
Messen wir, was wir messen wollen
Verschiedenen Möglichkeit der Qualitätssicherung
- Validierung hilft zu verstehen, wo wir falsch liegen und wie falsch wir liegen.
- Qualitätssicherung z.B. via (Jana Bernhard et al., 2023; Quinn et al., 2009) …
Theoretischer (!) Ableitung von Messungen (Chen et al., 2023)
Vergleich mit manueller Codierung (z.B. Chan & Sältzer, 2020)
Vergleich mit externen Ereignissen
Validieren, Validieren, Validieren
Kritisiche Anmerkungen zum Topic Modeling
Automated text analysis methods can substantially reduce the costs and time of analyzing massive collections of political texts. When applied to any one problem, however, the output of the models may be misleading or simply wrong. […] What should be avoided, then, is the blind use of any method without a validation step. (Grimmer & Stewart, 2013, p. S.5)
Klassifikationsmodell klassifiziert alle Dokumente, ein Diktionär spuckt für jedes Dokument ein Ergebnis aus, ein Topic Model findet immer die vorgegebene Anzahl an Themen.
Ob es sich dabei auch um inhaltlich sinnvolle Ergebnisse handelt, kann und muss durch manuelle Validierungen festgestellt werden.
Moderne Verfahren (z.B. BERT) potentiell besser geeignet für bestimmte Texte.
Hands on working with R
Various exercises on the content of today’s session
🧪 And now … you!
Next steps
- Laden das .zip-Archiv
stm_session_09.RData.zipvon StudOn herunter und entpacke die Dateien an einen Ort deiner Wahl. - Öffnet RStudio.
- Führt folgenden Code-Chunk aus:
- Ladet den Datensatz in die App.
- Macht euch mit den verschiedenen Funtionen der App vertraut und versucht, die Ergebnisse aus der Sitzung zu reproduzieren.
Time for questions
Bis zur nächsten Sitzung!
References
Breuer, J., & Haim, M. (2024). Are we replicating yet? Reproduction and replication in communication research. Media and Communication, 12. https://doi.org/10.17645/mac.8382
Chan, C., & Sältzer, M. (2020). Oolong: An r package for validating automated content analysis tools. Journal of Open Source Software, 5(55), 2461. https://doi.org/10.21105/joss.02461
Chen, Y., Peng, Z., Kim, S.-H., & Choi, C. W. (2023). What We Can Do and Cannot Do with Topic Modeling: A Systematic Review. Communication Methods and Measures, 17(2), 111–130. https://doi.org/10.1080/19312458.2023.2167965
Chung-hong Chan, Tim Schatto-Eckrodt, & Johannes Gruber. (2024). What makes computational communication science (ir)reproducible? Computational Communication Research, 6(1), 1. https://doi.org/10.5117/ccr2024.1.5.chan
Denny, M. J., & Spirling, A. (2018). Text Preprocessing For Unsupervised Learning: Why It Matters, When It Misleads, And What To Do About It. Political Analysis, 26(2), 168–189. https://doi.org/10.1017/pan.2017.44
Grimmer, J., & Stewart, B. M. (2013). Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts. Political Analysis, 21(3), 267–297. https://doi.org/10/f458q9
Jana Bernhard, Martin Teuffenbach, & Hajo G. Boomgaarden. (2023). Topic Model Validation Methods and their Impact on Model Selection and Evaluation. Computational Communication Research, 5(1), 1. https://doi.org/10.5117/ccr2023.1.13.bern
Long, J. A. (2021). Improving the replicability and generalizability of inferences in quantitative communication research. Annals of the International Communication Association, 45(3), 207–220. https://doi.org/10.1080/23808985.2021.1979421
Maier, D., Niekler, A., Wiedemann, G., & Stoltenberg, D. (2020). How Document Sampling and Vocabulary Pruning Affect the Results of Topic Models. Computational Communication Research, 2(2), 139–152. https://doi.org/10.5117/ccr2020.2.001.maie
Maier, D., Waldherr, A., Miltner, P., Wiedemann, G., Niekler, A., Keinert, A., Pfetsch, B., Heyer, G., Reber, U., Häussler, T., Schmid-Petri, H., & Adam, S. (2018). Applying LDA Topic Modeling in Communication Research: Toward a Valid and Reliable Methodology. Communication Methods and Measures, 12(2-3), 93–118. https://doi.org/10.1080/19312458.2018.1430754
Quinn, K. M., Monroe, B. L., Colaresi, M., Crespin, M. H., & Radev, D. R. (2009). How to Analyze Political Attention with Minimal Assumptions and Costs. American Journal of Political Science, 54(1), 209–228. https://doi.org/10.1111/j.1540-5907.2009.00427.x
Roberts, M. E., Stewart, B. M., & Tingley, D. (2016). Navigating the local modes of big data: The case of topic models (pp. 51–97). Cambridge University Press. https://doi.org/10.1017/cbo9781316257340.004
Roberts, M. E., Stewart, B. M., & Tingley, D. (2019). stm: An R Package for Structural Topic Models. Journal of Statistical Software, 91(1), 1–40. https://doi.org/10.18637/jss.v091.i02
Schwemmer, C. (2021). Stminsights: A shiny application for inspecting structural topic models. https://github.com/cschwem2er/stminsights
Wilkerson, J., & Casas, A. (2017). Large-Scale Computerized Text Analysis in Political Science: Opportunities and Challenges. Annual Review of Political Science, 20(1), 529–544. https://doi.org/10.1146/annurev-polisci-052615-025542
